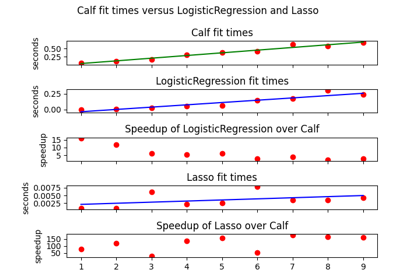
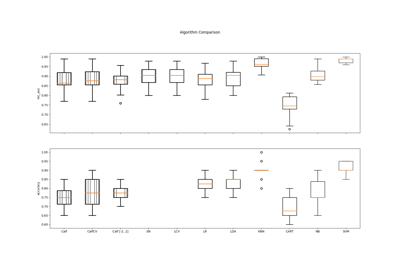
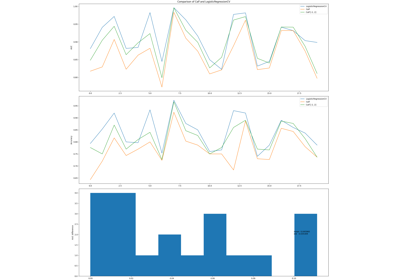
calfcv.Calf¶
- class calfcv.Calf(grid=(-1, 1), verbose=0)[source]¶
Course approximation linear function
CalfCV fits a linear model with coefficients w = (w1, …, wp) to maximize the AUC of the targets predicted by the linear function.
- Parameters:
- gridthe search grid. Default is (-1, 1).
- verbose0 is silent. 1-3 are increasingly verbose
Notes
The feature matrix must be centered at 0. This can be accomplished with sklearn.preprocessing.StandardScaler, or similar. No intercept is calculated.
Examples
>>> import numpy >>> from calfcv import Calf >>> from sklearn.datasets import make_classification as mc >>> X, y = mc(n_features=2, n_redundant=0, n_informative=2, n_clusters_per_class=1, random_state=42) >>> numpy.round(X[0:3, :], 2) array([[ 1.23, -0.76], [ 0.7 , -1.38], [ 2.55, 2.5 ]])
>>> y[0:3] array([0, 0, 1])
>>> cls = CalfCV().fit(X, y) >>> cls.score(X, y) 0.7
>>> cls.best_coef_ [1, 1]
>>> numpy.round(cls.best_score_, 2) 0.82
>>> cls.fit_time_ > 0 True
>>> cls.predict(np.array([[3, 5]])) array([0])
>>> cls.predict_proba(np.array([[3, 5]])) array([[1., 0.]])
- Attributes:
- coef_array of shape (n_features, )
Estimated coefficients for the linear fit problem. Only one target should be passed, and this is a 1D array of length n_features.
- auc_array of shape (n_features, )
The cumulative auc up to each feature.
- n_features_in_int
Number of features seen during fit.
- classes_list
The unique class labels
- fit_time_float
The number of seconds to fit X to y
- decision_function(X)[source]¶
Identify confidence scores for the samples
- Arguments:
- Xarray-like, shape (n_samples, n_features)
The training input features and samples
- Returns:
the decision vector (n_samples)
- fit(X, y)[source]¶
fit Calf to X and y
- Arguments:
- Xarray-like, shape (n_samples, n_features)
The training input features and samples
y : ground truth vector
- Returns:
self
- predict(X)[source]¶
Predict class labels for each sample
- Arguments:
- Xarray-like, shape (n_samples, n_features)
The training input features and samples
- Returns:
the class prediction of X (n_samples)
- predict_proba(X)[source]¶
Identify the probability of each sample class label
- Arguments:
- Xarray-like, shape (n_samples, n_features)
The training input features and samples
- Returns:
the class probabilities of X (n_samples)
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Calf¶
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
pipeline.Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.