Low feature importance and generalization failure in the N2 dataset¶
No features are particularly informative in the N2 dataset. Neither Lasso nor Ridge demonstrate skill by generalizing on unseen data from N2. The F-test selects the features MMP7, MDA-LDL, KITLG, FTL, CCL8 as significant but that significance needs to be interpreted in the context of the failed permutation test.
[73]:
# Adapted by Rolf Carlson from
# (1) "Permutation feature importance"
# https://scikit-learn.org/stable/modules/permutation_importance.html
# (2) # "Feature importances with a forest of trees"
# https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html#feature-importances-with-a-forest-of-trees
# Author: Rolf Carlson, Carlson Research LLC, <hrolfrc@gmail.com>
# License: 3-clause BSD
Data and model fitting¶
[74]:
input_file = "../../../data/n2.csv"
[75]:
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import Ridge, Lasso
from sklearn.inspection import permutation_importance
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
import time
import numpy as np
import pandas as pd
df = pd.read_csv(input_file, header=0, sep=",")
# The input data is everything except the first column
X = df.loc[:, df.columns != 'ctrl/case']
# The outcome or diagnoses are in the first ctrl/case column
y = df['ctrl/case']
# The header row is the feature set
feature_names = list(X.columns)
[76]:
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
Permutation feature importance with Lasso¶
Lasso shows no features are important
[77]:
clf = GridSearchCV(
estimator=Lasso(),
param_grid={'alpha': np.linspace(0.01, 2, 10)}
)
clf.fit(X_train, y_train)
[77]:
GridSearchCV(estimator=Lasso(),
param_grid={'alpha': array([0.01 , 0.23111111, 0.45222222, 0.67333333, 0.89444444,
1.11555556, 1.33666667, 1.55777778, 1.77888889, 2. ])})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=Lasso(),
param_grid={'alpha': array([0.01 , 0.23111111, 0.45222222, 0.67333333, 0.89444444,
1.11555556, 1.33666667, 1.55777778, 1.77888889, 2. ])})Lasso()
Lasso()
Lasso does not learn the training set
[78]:
clf.best_estimator_.score(X_train, y_train)
[78]:
0.0
[79]:
clf.best_estimator_
[79]:
Lasso(alpha=0.45222222222222225)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Lasso(alpha=0.45222222222222225)
Lasso has no skill in predicting the test set
[80]:
clf.best_estimator_.score(X_test, y_test)
[80]:
0.0
The permutation test using Lasso shows no features are informative
[81]:
scoring = ['r2', 'neg_mean_absolute_percentage_error', 'neg_mean_squared_error']
r_multi = permutation_importance(
clf, X_test, y_test, n_repeats=30, random_state=0, scoring=scoring)
for metric in r_multi:
print(f"{metric}")
r = r_multi[metric]
for i in r.importances_mean.argsort()[::-1]:
if r.importances_mean[i] - 2 * r.importances_std[i] > 0:
print(f" {feature_names[i]:<15}"
f"{r.importances_mean[i]:.3f}"
f" +/- {r.importances_std[i]:.3f}")
import pprint
pprint.pprint(r_multi)
r2
neg_mean_absolute_percentage_error
neg_mean_squared_error
{'neg_mean_absolute_percentage_error': {'importances': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'importances_mean': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]),
'importances_std': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])},
'neg_mean_squared_error': {'importances': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'importances_mean': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]),
'importances_std': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])},
'r2': {'importances': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'importances_mean': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]),
'importances_std': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])}}
Permutation feature importance with Ridge¶
Ridge is more accommodating of N2 than Lasso, but does not show any features as informative
[82]:
clf = GridSearchCV(
estimator=Ridge(),
param_grid={'alpha': np.linspace(0.01, 2, 20)}
)
clf.fit(X_train, y_train)
[82]:
GridSearchCV(estimator=Ridge(),
param_grid={'alpha': array([0.01 , 0.11473684, 0.21947368, 0.32421053, 0.42894737,
0.53368421, 0.63842105, 0.74315789, 0.84789474, 0.95263158,
1.05736842, 1.16210526, 1.26684211, 1.37157895, 1.47631579,
1.58105263, 1.68578947, 1.79052632, 1.89526316, 2. ])})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=Ridge(),
param_grid={'alpha': array([0.01 , 0.11473684, 0.21947368, 0.32421053, 0.42894737,
0.53368421, 0.63842105, 0.74315789, 0.84789474, 0.95263158,
1.05736842, 1.16210526, 1.26684211, 1.37157895, 1.47631579,
1.58105263, 1.68578947, 1.79052632, 1.89526316, 2. ])})Ridge()
Ridge()
Ridge would have us believe it learns the training data
[83]:
clf.best_estimator_.score(X_train, y_train)
[83]:
0.9989756581526885
Ridge has no skill in predicting the test set
[84]:
clf.best_estimator_.score(X_test, y_test)
[84]:
-1.1218334168295656
[85]:
clf.best_estimator_
[85]:
Ridge(alpha=2.0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Ridge(alpha=2.0)
No informative features identified by Ridge
[86]:
scoring = ['r2', 'neg_mean_absolute_percentage_error', 'neg_mean_squared_error']
r_multi = permutation_importance(
clf, X_test, y_test, n_repeats=30, random_state=0, scoring=scoring)
for metric in r_multi:
print(f"{metric}")
r = r_multi[metric]
for i in r.importances_mean.argsort()[::-1]:
if r.importances_mean[i] - 2 * r.importances_std[i] > 0:
print(f" {feature_names[i]:<15}"
f"{r.importances_mean[i]:.3f}"
f" +/- {r.importances_std[i]:.3f}")
r2
SERPINE1 0.156 +/- 0.070
THBS1 0.029 +/- 0.014
neg_mean_absolute_percentage_error
testosterone 46566004462502.430 +/- 19396365744214.027
CCL20 25517487168154.852 +/- 8941289017410.930
TIMP1 13964451950245.100 +/- 6502036937224.517
neg_mean_squared_error
SERPINE1 0.039 +/- 0.017
THBS1 0.007 +/- 0.004
Feature importances with a forest of trees¶
This example shows the use of a forest of trees to evaluate the importance of features on the N2 classification task. The blue bars are the feature importances of the forest, along with their inter-trees variability represented by the error bars.
A random forest classifier will be fitted to compute the feature importances.
[87]:
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
[87]:
RandomForestClassifier(random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(random_state=0)
[87]:
“Feature importances are provided by the fitted attribute feature_importances_ and they are computed as the mean and standard deviation of accumulation of the impurity decrease within each tree.” [1]
Warning
Impurity-based feature importances can be misleading for high cardinality features (many unique values). See permutation_importance as an alternative below.
[88]:
n_features = 20
start_time = time.time()
importances = forest.feature_importances_
std = np.std([tree.feature_importances_ for tree in forest.estimators_], axis=0)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
# get the top 10
importances_top, std_top, feature_names_top = zip(*sorted(zip(importances, std, feature_names), reverse=True)[0:n_features])
Elapsed time to compute the importances: 0.012 seconds
Let’s plot the impurity-based importance.
[89]:
import pandas as pd
forest_importances = pd.Series(importances_top, index=feature_names_top)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std_top, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
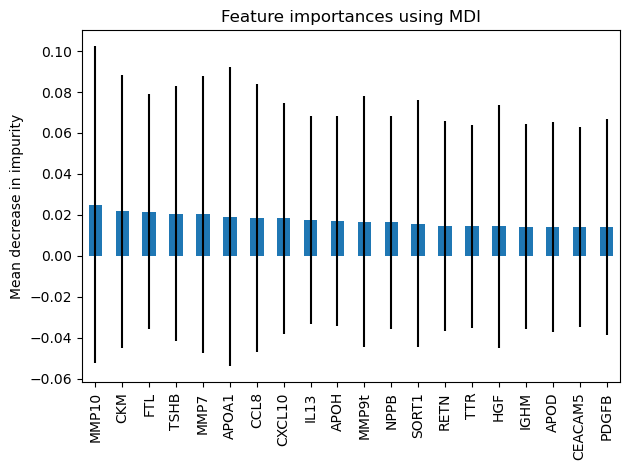
We observe that no features are found important.
“Permutation feature importance overcomes limitations of the impurity-based feature importance: they do not have a bias toward high-cardinality features and can be computed on a left-out test set.”
[90]:
from sklearn.inspection import permutation_importance
start_time = time.time()
n_features = 30
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
importances_top, std_top, feature_names_top = zip(*sorted(zip(forest_importances, result.importances_std, feature_names), reverse=True)[0:n_features])
Elapsed time to compute the importances: 7.829 seconds
“The computation for full permutation importance is more costly. Features are shuffled n times and the model refitted to estimate the importance of it. Please see permutation_importance for more details. We can now plot the importance ranking.”
[91]:
fig, ax = plt.subplots()
perm_importances = pd.Series(importances_top, index=feature_names_top)
pd.Series(importances_top, index=feature_names_top).plot.bar(yerr=std_top, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()
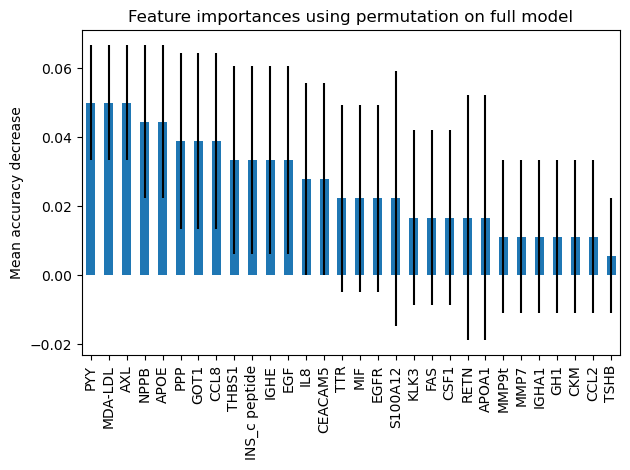
There is little contribution from any of the features.
Significant features by an F test¶
The F test is a univariate feature selection test. The F-test suggests that five of the features are significant: MMP7, MDA-LDL, KITLG, FTL, CCL8.
[92]:
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.preprocessing import StandardScaler
X_std = StandardScaler().fit_transform(X, y)
k_best = SelectKBest(f_classif, k=10)
X_new = k_best.fit_transform(X, y)
X_new.shape
[92]:
(72, 10)
[93]:
best_feature_names = [feature_names[i] for i in k_best.get_support(indices=True)]
best_feature_names
[93]:
['FTL',
'MMP7',
'MMP9',
'CCL8',
'CCL13',
'KITLG',
'TSHB',
'IL8',
'MMP1',
'MDA-LDL']
[94]:
# F-statistic for each feature.
df = pd.DataFrame(np.transpose([feature_names, k_best.scores_, k_best.pvalues_]), columns=['feature', 'F statistic', 'p-value'])
[95]:
df.dropna(inplace=True)
df['p-value'] = df['p-value'].astype(float)
[96]:
df[df['p-value'] < .05].sort_values('p-value')
[96]:
| feature | F statistic | p-value | |
|---|---|---|---|
| 39 | MMP7 | 8.065753347833445 | 0.005902 |
| 134 | MDA-LDL | 5.863674628530396 | 0.018051 |
| 61 | KITLG | 5.055033950829319 | 0.027705 |
| 26 | FTL | 4.909920374385786 | 0.029956 |
| 43 | CCL8 | 4.385681836222313 | 0.039864 |
[96]: